ZooKeeper или пишем сервис распределенных блокировок
10 мин
disclaimer Так получилось, что последний месяц я разбираюсь с ZooKeeper, и у меня возникло желание систематизировать то, что я узнал, собственно пост об этом, а не о сервисе блокировок, как можно было подумать исходя из названия. Поехали!
При переходе от многопоточного программирования к программированию распределенных систем многие стандартные техники перестают работать. Одной из таких техник являются блокировки (synchronized), так как область их действия ограничена одним процессом, следовательно, они не только не работают на разных узлах распределенной системы, но так же не между разными экземплярами приложения на одной машине; получается, что нужен отдельный механизм для блокировок.
От распределенного сервиса блокировок разумно требовать:
Создать подобный сервис нам поможет ZooKeeper
 В википедии написано, что ZooKeeper — распределенный сервис конфигурирования и синхронизации, не знаю как вам, но мне данное определение мало что раскрывает. Оглядываясь на свой опыт, могу дать альтернативное определение ZooKeeper, это распределенное key/value хранилище со следующими свойствами:
В википедии написано, что ZooKeeper — распределенный сервис конфигурирования и синхронизации, не знаю как вам, но мне данное определение мало что раскрывает. Оглядываясь на свой опыт, могу дать альтернативное определение ZooKeeper, это распределенное key/value хранилище со следующими свойствами:
При переходе от многопоточного программирования к программированию распределенных систем многие стандартные техники перестают работать. Одной из таких техник являются блокировки (synchronized), так как область их действия ограничена одним процессом, следовательно, они не только не работают на разных узлах распределенной системы, но так же не между разными экземплярами приложения на одной машине; получается, что нужен отдельный механизм для блокировок.
От распределенного сервиса блокировок разумно требовать:
- работоспособность в условиях моргания сети (первое правило распределенных систем —
никому не говорить о распределенных системахсеть ненадежна) - отсутствие единой точки отказа
Создать подобный сервис нам поможет ZooKeeper
В википедии написано, что ZooKeeper — распределенный сервис конфигурирования и синхронизации, не знаю как вам, но мне данное определение мало что раскрывает. Оглядываясь на свой опыт, могу дать альтернативное определение ZooKeeper, это распределенное key/value хранилище со следующими свойствами:- пространство ключей образует дерево (иерархию подобную файловой системе)
- значения могут содержаться в любом узле иерархии, а не только в листьях (как если бы файлы одновременно были бы и каталогами), узел иерархии называется znode
- между клиентом и сервером двунаправленная связь, следовательно, клиент может подписываться как изменение конкретного значения или части иерархии
- возможно создать временную пару ключ/значение, которая существует, пока клиент её создавший подключен к кластеру
- все данные должны помещаться в память
- устойчивость к смерти некритического кол-ва узлов кластера

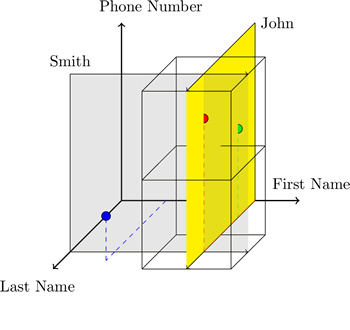
 Одна из самых разрекламированных фич MongoDB — это гибкость. Я сам не раз подчеркивал это в бесчисленных разговорах о MongoDB. Однако, гибкость — это палка о двух концах: большая гибкость подразумевает более широкий выбор решений для моделирования данных. Тем не менее, мне нравится гибкость, которую предоставляет MongoDB, просто нужно иметь ввиду некоторые рекомендации, прежде чем начать разрабатывать модель данных.
Одна из самых разрекламированных фич MongoDB — это гибкость. Я сам не раз подчеркивал это в бесчисленных разговорах о MongoDB. Однако, гибкость — это палка о двух концах: большая гибкость подразумевает более широкий выбор решений для моделирования данных. Тем не менее, мне нравится гибкость, которую предоставляет MongoDB, просто нужно иметь ввиду некоторые рекомендации, прежде чем начать разрабатывать модель данных.