Здесь стоит уточнить, что поскольку система AS основана на API, в ее задачи не входит мгновенное предоставление ресурсов по требованию, в момент появления необходимости в них, или угадывание/предсказывание будущей необходимости в ресурсах. Суть AS заключается в том, что он должен зафиксировать момент, когда можно с уверенностью сказать, что ресурсов текущего тарифного плана становится недостаточно для гарантированного
* и своевременного
** выполнения запущенных на виртуальной машине процессов, и автоматически перевести ВМ на следующий тариф.
**Своевременного — потому что, если выполнение запущенных процессов упирается в процессорный ресурс, то процессы так или иначе выполнятся. Но время их завершения становится непредсказуемым.
*Гарантированного, потому что если оперативная память ВМ близка к исчерпанию и на ВМ не настроен swap, то это означает, что близка ситуация, когда какой-то из запущенных на ВМ процессов будет аварийно завершен операционной системой, если суммарное потребление памяти всеми процессами превысит ее общий объем. Если же swap настроен, то пока он также не исчерпается, никто убит не будет, но быстродействие ВМ также сильно просядет, т.к. будет зависеть от скорости работы swap-раздела, которая в любом случае на порядок меньше, чем скорость работы оперативной памяти.







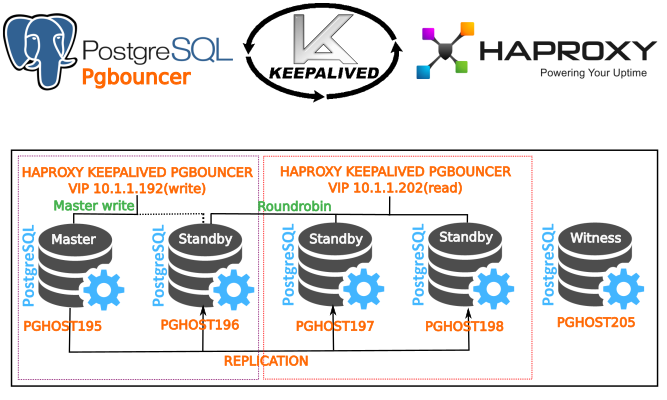

 Недавно мы перевели Zabbix на работу с БД PostgreSQL. Вместе с переездом на сервер с SSD это дало существенный прирост скорости работы. Также решили проблему с дублирующими хостами в базе данных,
Недавно мы перевели Zabbix на работу с БД PostgreSQL. Вместе с переездом на сервер с SSD это дало существенный прирост скорости работы. Также решили проблему с дублирующими хостами в базе данных, 
