Астрология и Data mining
4 мин
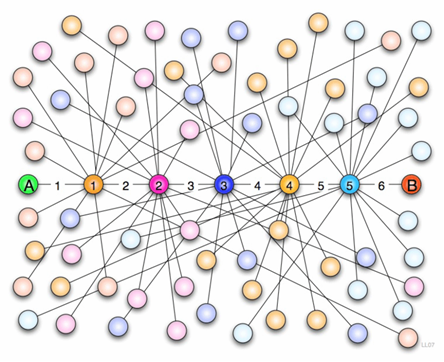
Как и многие люди технического склада ума, я с крайним недоверием отношусь к астрологии, гороскопам и прочим псевдонаукам. Моё мировозрение пошатнулось когда я от скуки решил изучить влияение времени года в которое рождается человек, на его психические особенности. Оценка психических особенностей производилась по результатам соционического теста из приложения VK, которое насчитывает более 500000 пользователей. Надёжность и валидность теста небольшая, да и вся соционическая модель имеет ряд проблем. Но нам важно другое: понять есть ли хоть какие-то отличия между людьми родившимися в разное время. Объём выборки в полмиллиона человек позволяет надеяться на положительный результат. В ходе исследования ожидалось получить линейную зависимость между продолжительностью светлого времени суток в день рождения человека и его психотипом, но получилось
 Вы звоните провайдеру. Приготовившись к разговору с вымученно-жизнерадостной девушкой о количестве зелёных лампочек на чёрной коробочке, даже немного теряетесь, когда вам отвечает натуральный сисадмин. И сразу же понимает суть проблемы и решает её. Вы кладёте трубку через 25 секунд разговора в лёгком шоке.
Вы звоните провайдеру. Приготовившись к разговору с вымученно-жизнерадостной девушкой о количестве зелёных лампочек на чёрной коробочке, даже немного теряетесь, когда вам отвечает натуральный сисадмин. И сразу же понимает суть проблемы и решает её. Вы кладёте трубку через 25 секунд разговора в лёгком шоке. 

 Во всех онлайн сервисах и играх самая большая доля аудитории уходит прямо на старте – в первые же минуты и часы знакомства с продуктом. Этой теме уже посвящены сотни книг и статей с самыми различными гипотезами успеха и причин лояльности аудитории – уникальность, простота, юзабилити, бесплатность, обучение или инструкция, эмоциональность, и еще множество факторов считаются крайне важными.
Во всех онлайн сервисах и играх самая большая доля аудитории уходит прямо на старте – в первые же минуты и часы знакомства с продуктом. Этой теме уже посвящены сотни книг и статей с самыми различными гипотезами успеха и причин лояльности аудитории – уникальность, простота, юзабилити, бесплатность, обучение или инструкция, эмоциональность, и еще множество факторов считаются крайне важными.